NuCache KeyNote : Snapshots
Posted on July 7, 2016 in umbraco
CodeGarden '16 was a blast and it all went so fast! Trying to explain NuCache in under five minutes during the KeyNote sure was an... interesting exercise. Bit frustrating, maybe. So, this post tries to go through some of the concepts that were introduced, in a more relaxed and detailed way.
Snapshots
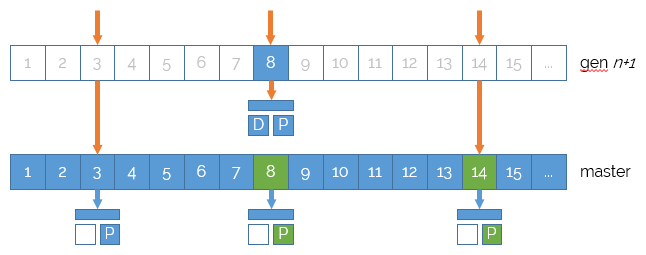
NuCache essentially is one thread-safe dictionary using the content identifier as a key. For each identifier, it contains a pair: the draft (unpublished) version, if any, and the published version, if any. In the following diagram, content item #3 is published, content item #14 is not published, and content item #8 is published, and has some unpublished changes.

That master dictionary is, however, never accessed directly. NuCache content is accessed through snapshots which are, essentially, another thread-safe dictionary on top of the master dictionary. As long as no changes are made to content, the snapshot dictionary is empty, and every read operation goes through it and reaches the master dictionary.
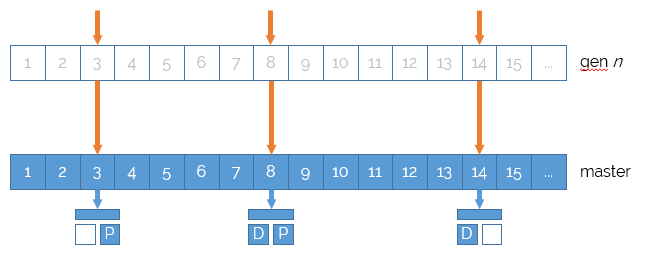
Now, if some changes are made, e.g. in the following diagram, publishing content item #14, the original state is copied into the snapshot dictionary. That way, the master dictionary contains the actual, modified, content item, whereas the snapshot dictionary contains the original content item.
A read operation on that content item would stop at the snapshot dictionary level, and return the original content item, thus shielding readers from seeing changes.
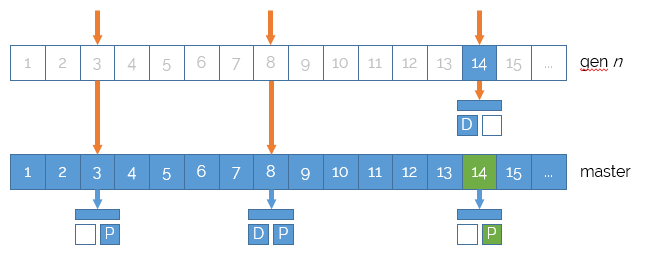
When a new snapshot is requested, NuCache inserts a new snapshot dictionary at the bottom of the stack.
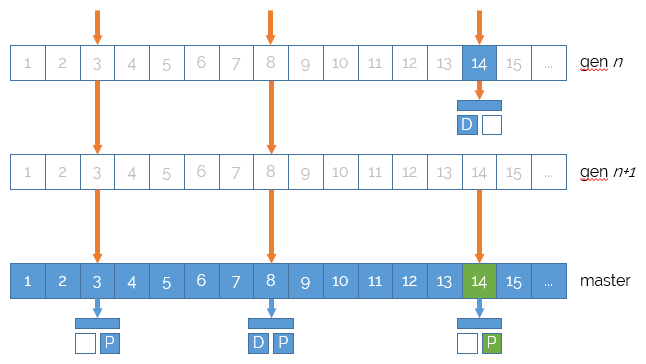
When changes are made, e.g. in the following diagram, publishing content item #8, the original content item is copied into the bottom-most snapshot dictionary. Therefore, readers of that snapshot and any older snapshot will not see the change.
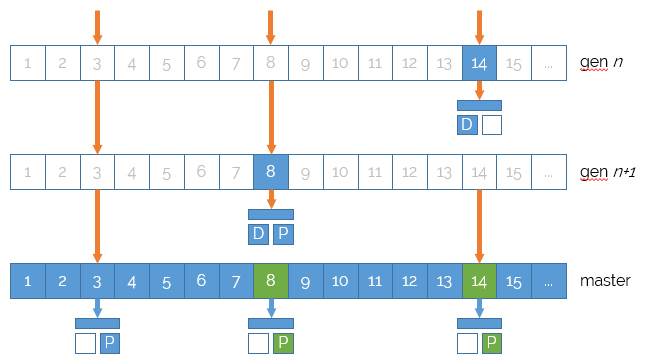
Eventually, the operations using the first snapshot will complete (e.g. the views will be rendered and the requests will be closed) and they will drop their reference to the snapshot. When no operation references the snapshot anymore, it is collected.
A new snapshot is created only when the previous snapshot contains changes. In other words, as long as no content item is published, NuCache runs with only one snapshot. When some content item are published, new snapshots are created—and the old ones survive only long enough as to allow the current requests to complete.
In addition, a throttling mechanism ensures that NuCache does not create hundreds of snapshots in a very short time (during, for example, a bulk-publish operation). The number of existing snapshots at any point of time should therefore remain relatively low.
Hopefully it all makes more sense now!
There used to be Disqus-powered comments here. They got very little engagement, and I am not a big fan of Disqus. So, comments are gone. If you want to discuss this article, your best bet is to ping me on Mastodon.